Deploying a model
Learn how to deploy any machine learning model on Hathora using Docker containers. This guide demonstrates the complete process from creating an app to serving inference requests with load balancing and autoscaling.
What You Can Deploy
Hathora's flexible container platform supports any workload that can be containerized, including:
- Large Language Models (LLMs) - GPT, LLaMA, Mistral, etc.
- Vision Models - Image classification, object detection, segmentation
- Audio Models - Speech recognition, text-to-speech, music generation
- Custom ML Pipelines - Data processing, feature extraction, ensemble models
- API Services - REST APIs, WebSocket servers, microservices
As long as your workload runs in a Docker container and exposes a network port, you can deploy it on Hathora.
Prerequisites
- A Hathora account (sign up here)
- Basic familiarity with Docker and REST APIs
- A containerized ML model. For this guide we'll use a pre-built container on DockerHub:
andrehathora/hathora-sglang
Step 1: Create Application
- Go to console.hathora.dev
- Click "Create Application"
- Enter a name (e.g., "sglang-inference")
- Select
Load balanced endpoint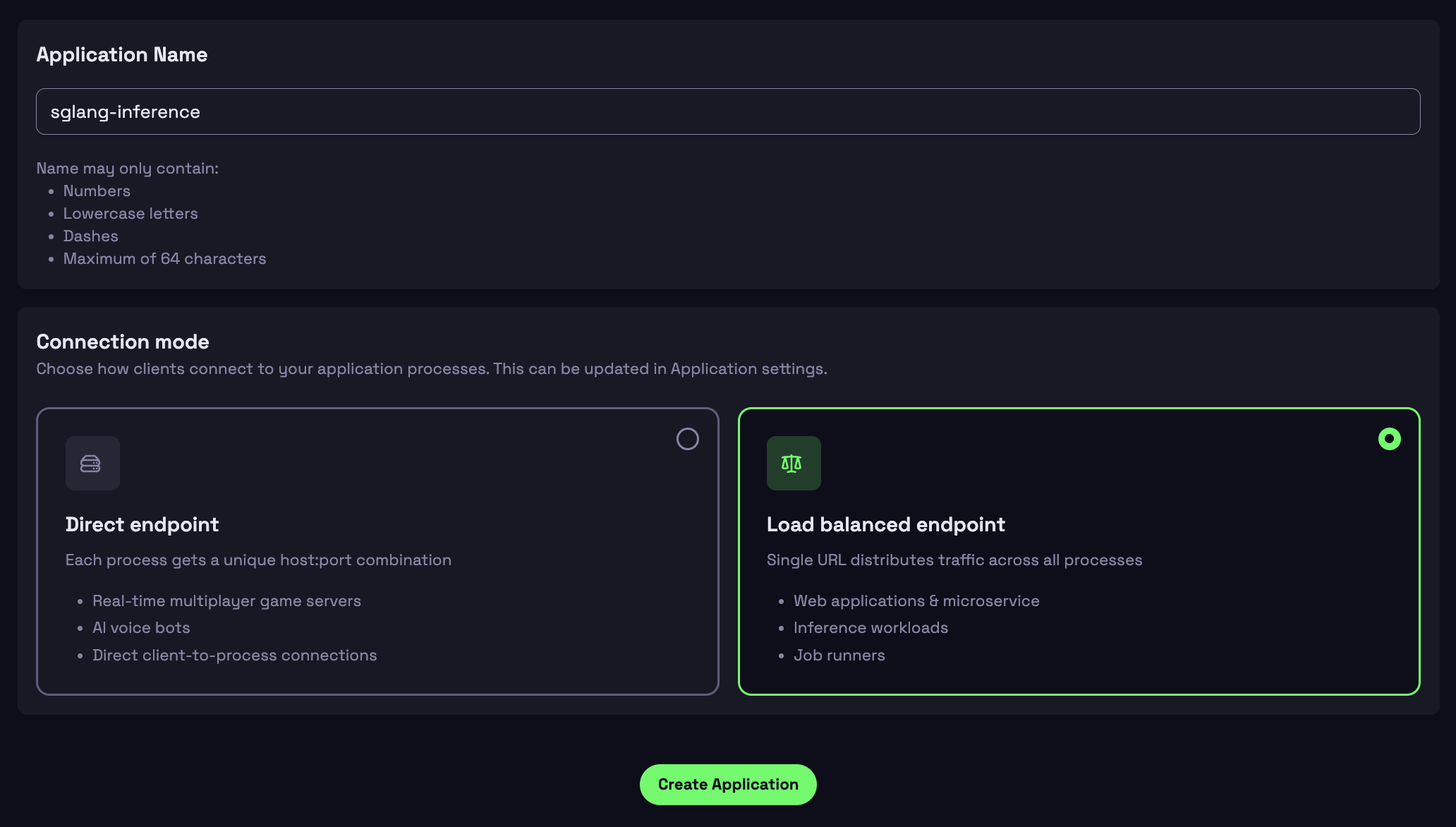
Step 2: Provide a docker build
-
Select External Registry Tab
-
Configure Your Build
- Image name: andrehathora/hathora-sglang
- Registry URL: Leave blank (defaults to Docker Hub)
- Registry token: Leave blank (public image)
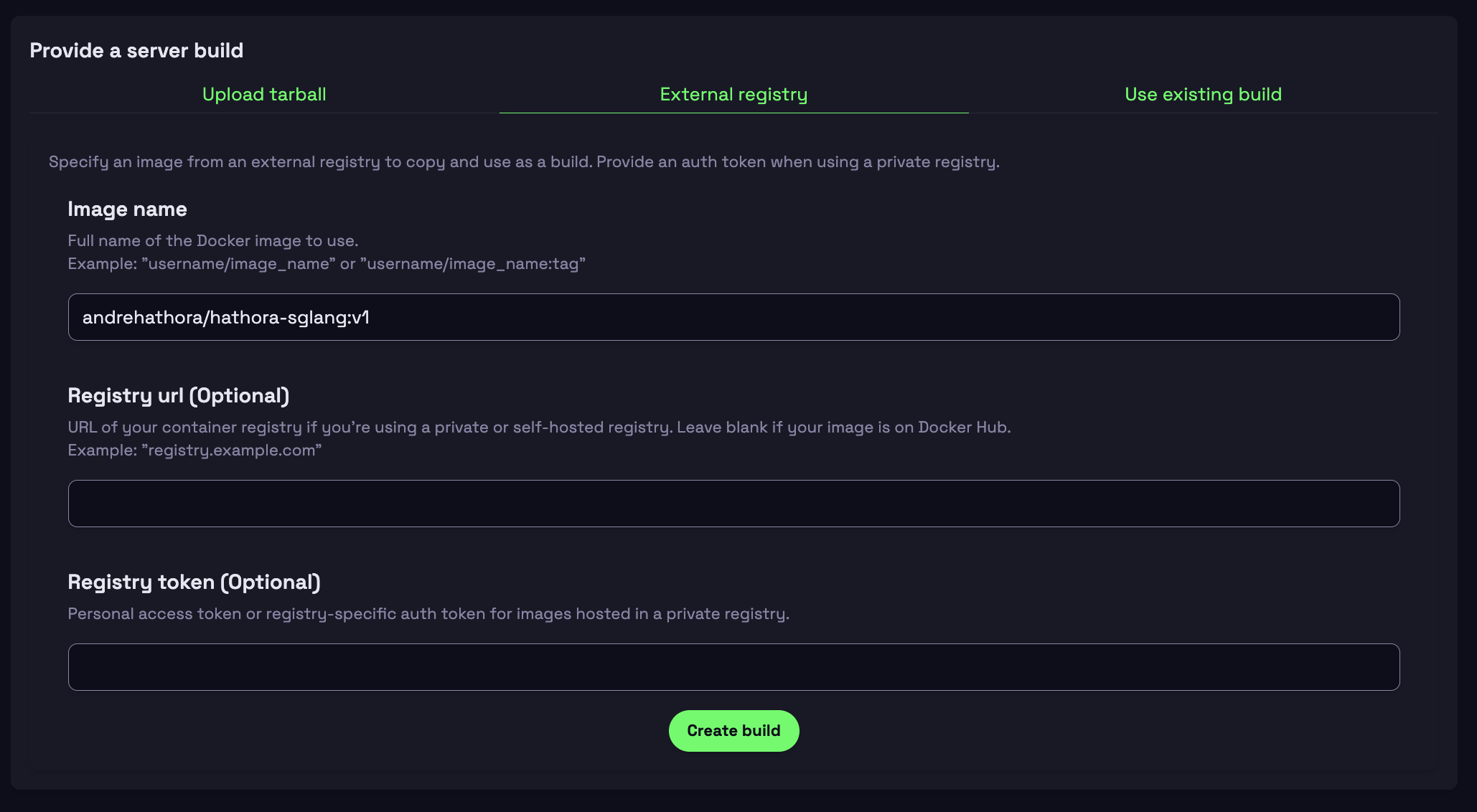
-
Click Create Build
- You will see logs of the container getting built
For the purpose of this example, we're using a publically available container. Alternatively you can provide a custom docker container with a Dockerfile at the root of the directory.
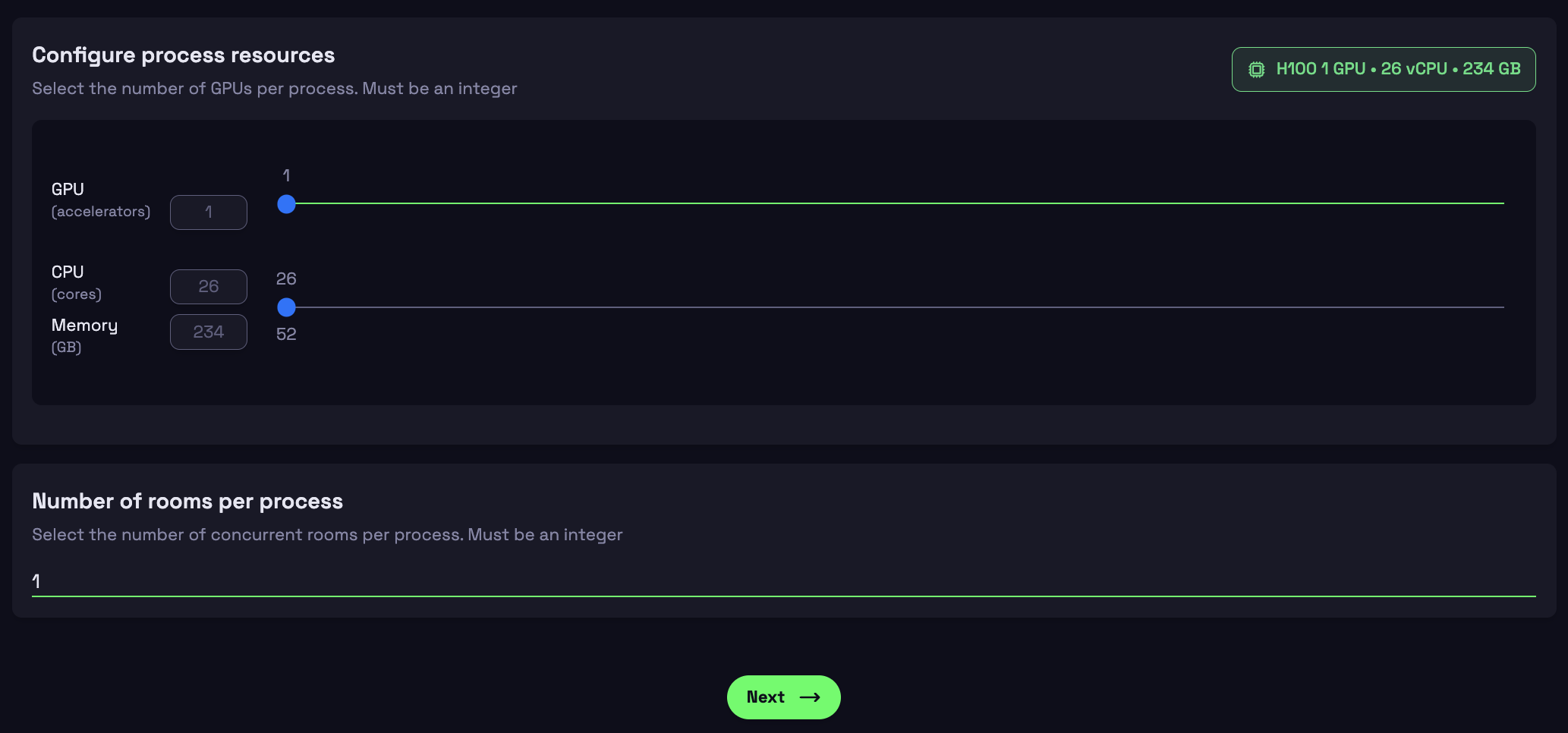
Step 3: Create Deployment
- Configure the container's resources:
- 1 H100 GPU, 26 vCPU, 234 GB
- Keep Number of rooms per process = 1
- For Transport, set the Port for where the container is listening on
- In this example it is port
8000
- In this example it is port
- Set Environment Variables:
- Name:
MODEL_PATH - Variable:
Qwen/Qwen2.5-7B-Instruct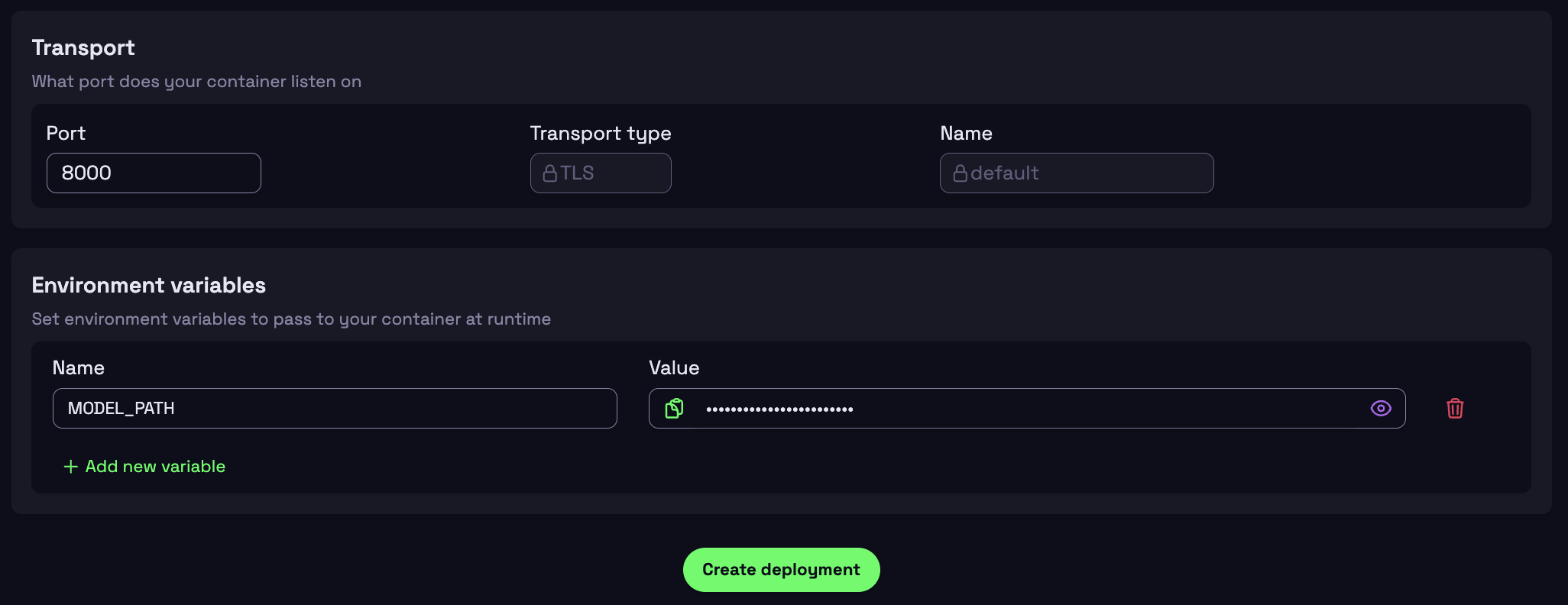
- Name:
- Click Create Deployment
Step 4: Connect to your model
-
Grab the App URL from the Console
-
Test connectivity
- Hit the endpoint using a
cURLcommand
curl https://your-app-url - Hit the endpoint using a